If a web page is not indexed by Google, then Google will not show it in the search results. Due to Google low-quality content penalty and crawl budget management, you may want Google not to index some pages on your website.
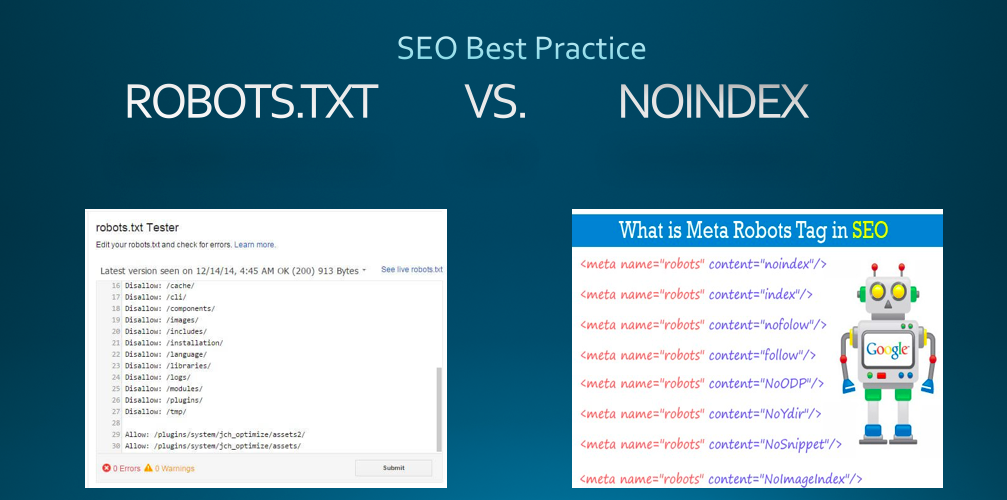
To do that, you can either add an noindex tag to the pages that you do not want Google to index or set up robot.txt file to block Googlebots from crawling these pages.
What is a NoIndex Tag?
A NoIndex tag is an instruction that tells search engines (including Google, Bing, Yahoo, etc.) not to show a certain page in their search results. Search engines will still crawl the pages with a noindex tag, but less frequently as time goes.

Should you use noindex tag or robots.txt?
Robots.txt is a text file at the root of your site to instruct search engine robots not to crawl some pages on your website. You can configure robots.txt file to indicate whether a search engine robot can or cannot crawl pages of your website.
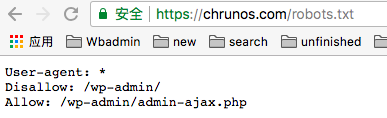
When you use a “disallow” line in robots.txt, it tells bots not to crawl these pages, so links on these pages does not pass link juice. However, when other pages link to the robotted pages, these pages ay still get indexed and show up in the search results.
Therefore, to properly prevent some URLs from appearing in search results, you should use Noindex tag.
Robots.txt should be configured when you first launch your website. You can also change it when you want to block new categories or pages.
If a page is already indexed, robots.txt cannot remove it from indexing. If you want to remove a page from indexing, you should only use noindex tag. If you use both noindex tag and robots.txt, web bots cannot access the page and read the noindex tag.
When to use noindex tag?
As mentioned, you should use noindex on pages that search engines might consider to be of poor quality.
Some examples for using noindex tag
Thin or low-quality content that you want to keep them for your users (In-site search results)
Pages created for other marketing purposes (Thank-you page, email marketing landing page). If search user land on these page, it may mix your analytics results.
Any page that you only want people to find it through a specific link.
User-generated content like forum pages if not moderated.
As mentioned, a NoIndex tag does not tell a search engine not to crawl a page. It will only crawl less frequently as it keeps seeing the noindex tag. Links in a page with noindex tag will pass links juice.
If you want links not to pass link juice, add a nofollow tag. You should also add a nofollow tag to links that pointing to pages with a noindex tag.
How do you implement a NoIndex tag?
After you identify the pages that you do not want search engines to index, place the noindex tag in the head section of these pages.
The noindex tag is like these:
<meta name=”robots” content=”noindex”>
If you want to search engines to quickly remove some pages from index, you can submit the noindex tagged pages to the webmaster tool.
Some cases that noindex tag is not recommended
Besides noindex tag, there are more tags to use. Use each tag correctly to get the best SEO value.
When you are dealing with duplicate content, you should use Rel=Canonical tag to indicate cononicalized version or 301 redirect to the preferred version.
For paginated content SEO, you should use Rel=Prev and Rel=Next rather than noindex because pages with noindex tag will eventually stop passing link juice.
Conclusion
Noindex tag is telling search engines not to index a page while robots.txt is telling search engines not to crawl a page. It is different, but sometimes both can serve the same purpose. If a page never allowed to crawl, it certainly will not be indexed.
Never crawled pages cannot pass PageRank, but pages with a noindex tag do pass PageRank.
Hopefully, this can help you better understand noindex and robots.txt. if not, leave your questions down below. What’s your best practice for noindex in 2018?